本文目录一览:
进化带给人类的四种学习方式
1、进化带给人类的四种学习方式分别为强化学习(试错学习)、通过新皮层假设(想象学习)、通过镜像神经元模仿学习、通过语言和文字从他人想象中学习,以下是详细介绍:强化学习(试错学习)起源与主体:从脊椎动物开始出现。
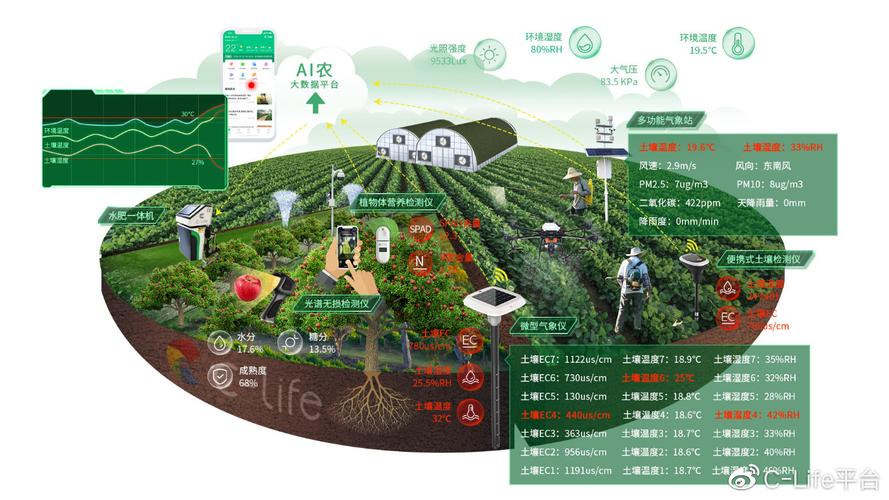
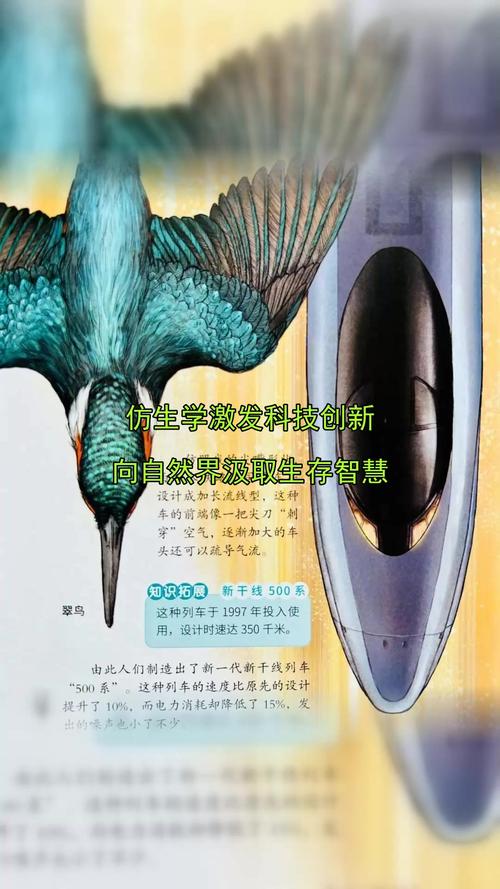
2、工程学启发 结构设计:动物的身体结构经过数百万年的进化,具有很高的适应性。通过研究动物的结构,可以获取借鉴,优化工程设计,提高材料强度和耐用性。运动机理:动物的运动方式和机理对于机械工程和运动控制具有启发作用,如鸟类飞行、鱼类游泳等,可用于改善航空、航天、水下机器人等领域的设计与控制。
3、个性化的学习方式:未来人类可能通过个性化的学习方式,根据自身需求和兴趣选择学习内容,实现更高效的学习和个人发展。劳动与工作:机器人时代的变革:随着机器人和自动化技术的普及,未来人类可能转向更创造性和智能化的工作,传统职业可能被机器人取代。
4、人类独特的生存策略在于改变进化的速度,并没有强化自身的攻击性特征,而是延长了妊娠期和儿童期。这种策略导致了大脑的显著发展,增强了求知本能、模仿本能和记忆力。 这些进化特征使得早期人类能够持续探索、模仿和学习,从而积累大量的知识和技能。语言和文字的出现进一步促进了知识的传承。
5、智力进化:科技进步:通过不断学习和应用新知识,人类智力水平在整体上得到提升。科技的发展为人类提供了更多的学习资源和工具,促进了智力的进化。教育与文化积累:教育和文化的传承使得人类能够积累前人的智慧,站在巨人的肩膀上继续前行,这也是智力进化的一种重要方式。
6、人们通过学习、阅读和思考来理解和应用这些遗产,进而不断发展和拓展我们的智慧。从教育和学习角度看,人的智慧也是通过教育、学习和经验的积累不断提高的。尤其是在现代文明社会,人们可以通过接受系统化、科学化的教育,以及利用现代技术工具,更加高效地获取信息和知识。
打破社交封闭=强化学习+好奇心算法
1、打破社交封闭可通过强化学习机制主动适应新社交场景,结合好奇心算法驱动对新社交关系的探索,二者协同作用能有效突破社交封闭状态。具体分析如下:强化学习在打破社交封闭中的作用适应新社交场景的机制:强化学习通过“试错—反馈—调整”的循环优化行为策略。
2、社交与沟通:组织家庭辩论、角色扮演游戏,提升孩子表达与共情能力。创新思维:鼓励孩子拆解日常物品(如玩具、家电),理解其原理后提出改进方案。自主学习习惯:设定“无屏幕时间”,让孩子自主规划学习内容,培养好奇心驱动的学习模式。
3、强化实践验证:将好奇心转化为行动,通过实验、创作或社交验证假设。例如,对心理学理论感兴趣时,可设计简单实验观察行为反应,或参与相关社群讨论实践案例。注意事项:避免将好奇心局限于“有用性”,允许对纯粹兴趣的探索(如星空观测、语言游戏)。
4、正向强化:当狗狗主动接近马桶或尝试使用时,立即表扬并奖励,强化行为与积极结果的关联。耐心纠正:若狗狗仍选择地面排泄,避免惩罚(如打骂),而是温和引导至马桶,避免因负面体验产生抵触情绪。拉布拉多的偷窥和模仿行为,本质是好奇心、学习能力和社交需求的综合体现。
5、终身学习的心态:保持对新知识的好奇心,主动接触陌生领域。例如,学习一门新语言或技能,能打开新的社交与职业机会。 社交与交流:在互动中打破偏见与不同背景的人交往是突破认知局限的有效方式:倾听多元声音:通过对话了解他人的生活经历与价值观,避免以己度人。
6、明确自身性格、优缺点、喜好及人生目标,建立清晰的自我认知。例如,若性格内向,可针对性地设定社交目标;若缺乏行动力,则需强化目标导向思维。自我认知是勇敢的基础,只有清楚“为何而战”,才能坚定行动方向。
强化学习简介
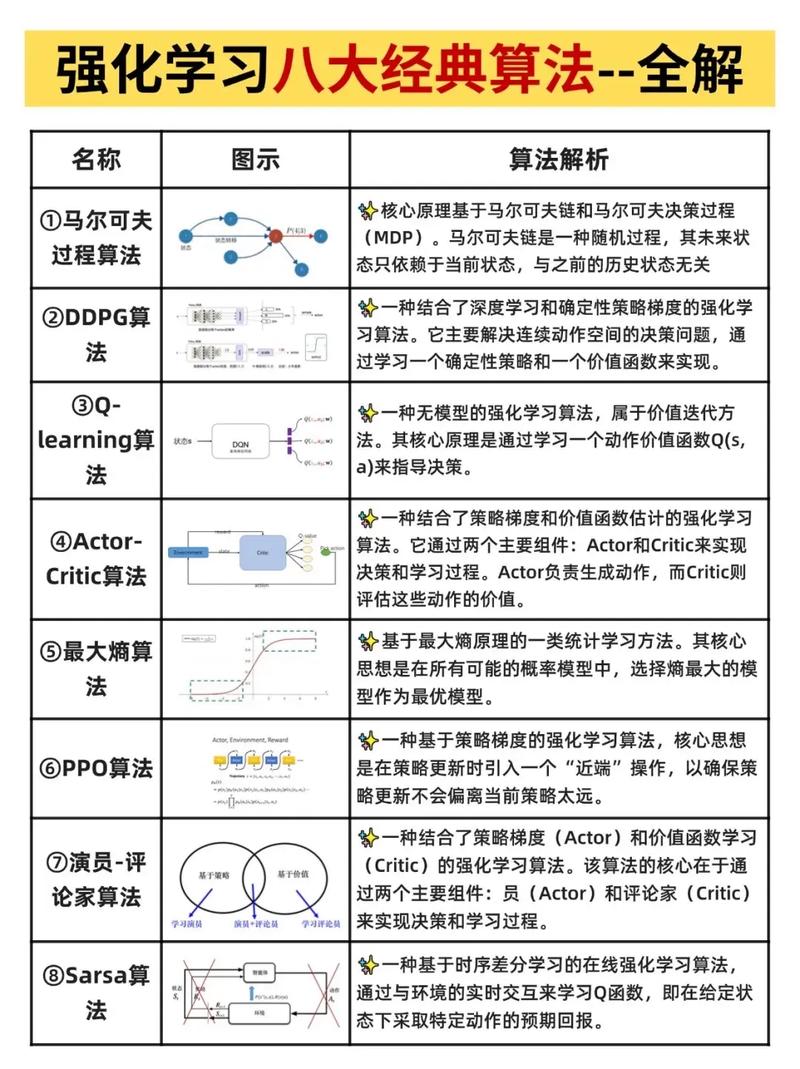
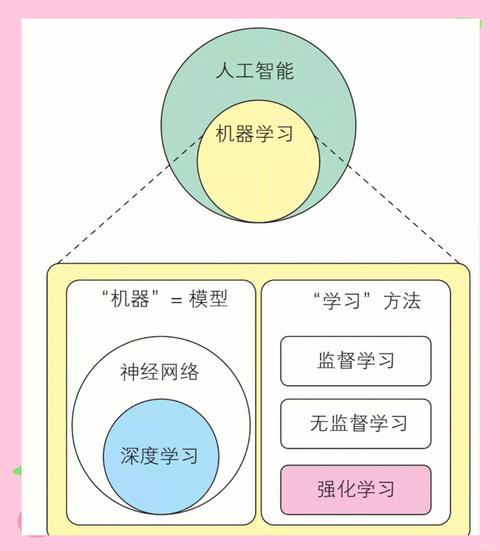
1、强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,它研究智能体(Agent)如何在与环境的交互中学习策略,以最大化某种累积奖励。以下是对强化学习的详细介绍:强化学习问题 强化学习问题可以定义为智能体与环境之间的交互过程。
2、强化学习(Reinforcement Learning, RL)是一种让智能体通过与环境交互、试错学习来优化决策策略的机器学习方法,其核心目标是最大化累积奖励。以下是强化学习的关键要点:基本概念强化学习基于马尔可夫决策过程(MDP),包含以下核心要素:智能体(Agent):执行动作并接收反馈的学习主体。
3、离线强化学习:利用历史数据训练策略,减少实时交互成本。可解释性增强:通过注意力机制或符号推理提升决策透明度。强化学习通过策略、价值或混合架构,在动态环境中实现自主决策优化,其算法选择取决于问题特性(如动作空间类型、样本效率需求)。
关注!美国陆军开发强化学习方法!
研究背景与目标未来战场需求美国陆军作战能力发展司令部陆军研究实验室的杰明·乔治博士指出,未来多领域战斗需要动态耦合、协调的异构移动平台(如无人机和无人地面车辆)来应对敌方威胁。传统方法依赖集中式控制,但计算复杂性和通信要求极高,导致学习时间过长,无法满足实时决策需求。
强化学习:作为核心人工智能算法,强化学习通过智能体与环境的交互学习最优策略,适用于军事场景中的动态决策问题。例如,在模拟对抗中训练人工智能指挥官,优化资源分配与战术选择。兵棋推演模拟:利用游戏化框架构建兵棋推演系统,支持多智能体协同与对抗训练。
网络攻防能力强化自动化漏洞检测与利用美国陆军网络司令部利用人工智能算法对目标系统进行实时扫描,快速识别潜在漏洞并自动生成攻击路径。例如,通过机器学习模型分析网络流量模式,可精准定位未修复的漏洞,缩短攻击准备周期。
决策能力升级:AI与士兵共同适应信息不足或欺骗性环境,通过元学习和元推理实现跨领域互动模拟,提升战术与战略弹性。流程加速:消除繁琐计算延迟,使计划与战略适应速度超越实时战场变化,同时整合外交、经济等外部因素。
美国陆军的融合项目(Project Convergence)是陆军推动的“学习运动”,旨在通过技术整合与跨军种协同,将自身深度融入联合部队体系,支撑国防部“联合全域指挥与控制”(JADC2)战略,提升对高端威胁的快速响应能力。